publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- ICLR
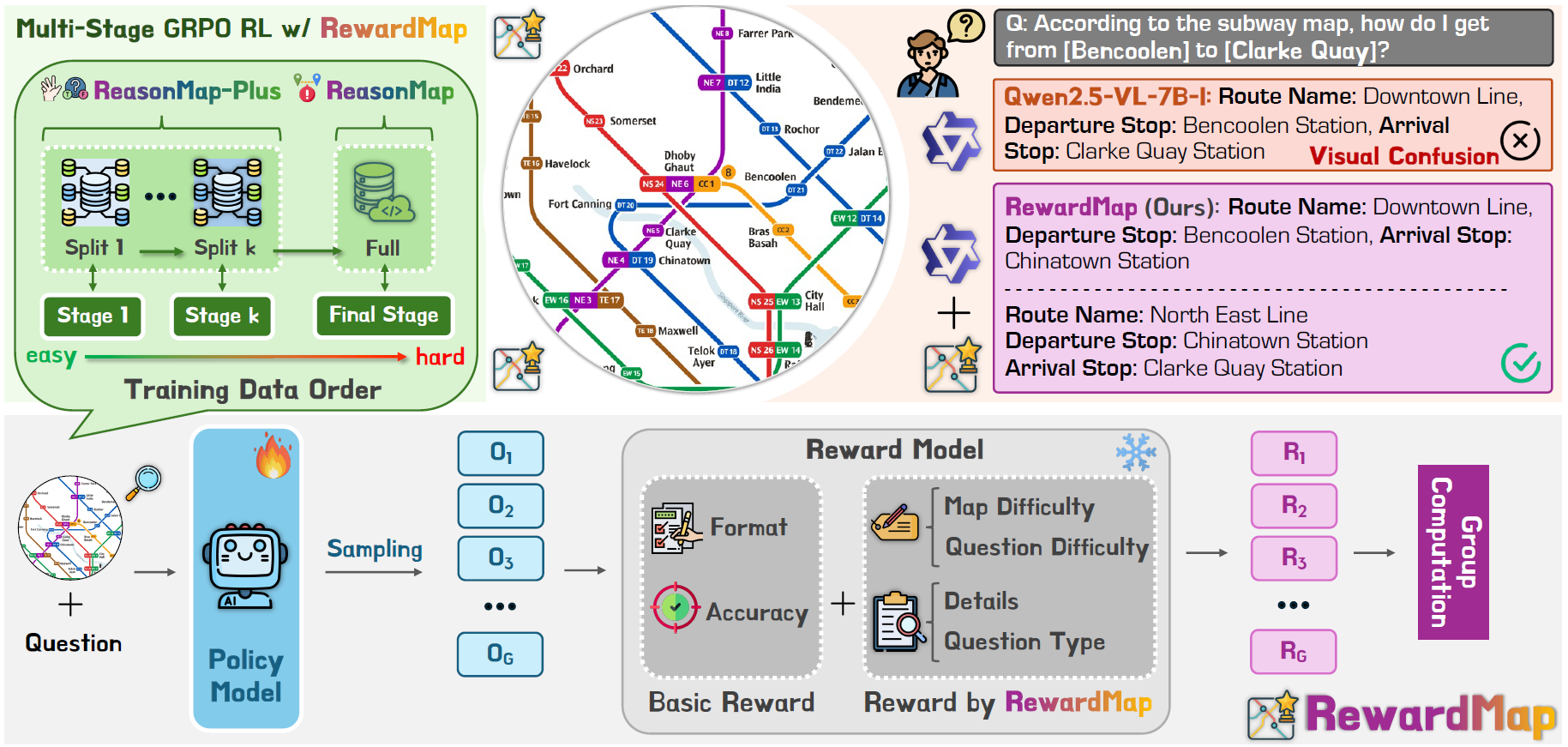 RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement LearningSicheng Feng†, Kaiwen Tuo† , Song Wang , and 3 more authorsICLR, 2026
RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement LearningSicheng Feng†, Kaiwen Tuo† , Song Wang , and 3 more authorsICLR, 2026Fine-grained visual reasoning remains a core challenge for multimodal large language models (MLLMs). The recently introduced ReasonMap highlights this gap by showing that even advanced MLLMs struggle with spatial reasoning in structured and information-rich settings such as transit maps, a task of clear practical and scientific importance. However, standard reinforcement learning (RL) on such tasks is impeded by sparse rewards and unstable optimization. To address this, we first construct ReasonMap-Plus, an extended dataset that introduces dense reward signals through Visual Question Answering (VQA) tasks, enabling effective cold-start training of fine-grained visual understanding skills. Next, we propose RewardMap, a multi-stage RL framework designed to improve both visual understanding and reasoning capabilities of MLLMs. RewardMap incorporates two key designs. First, we introduce a difficulty-aware reward design that incorporates detail rewards, directly tackling the sparse rewards while providing richer supervision. Second, we propose a multi-stage RL scheme that bootstraps training from simple perception to complex reasoning tasks, offering a more effective cold-start strategy than conventional Supervised Fine-Tuning (SFT). Experiments on ReasonMap and ReasonMap-Plus demonstrate that each component of RewardMap contributes to consistent performance gains, while their combination yields the best results. Moreover, models trained with RewardMap achieve an average improvement of 3.47% across 6 benchmarks spanning spatial reasoning, fine-grained visual reasoning, and general tasks beyond transit maps, underscoring enhanced visual understanding and reasoning capabilities.
- TMLR
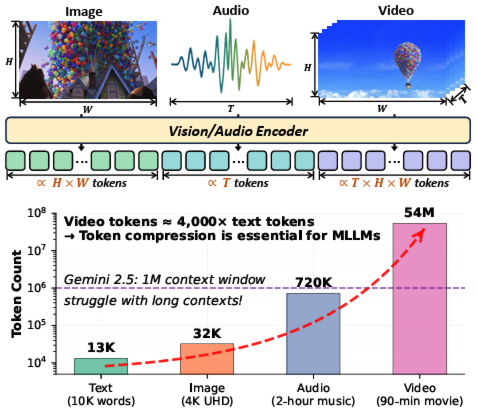 When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and AudiosKele Shao† , Keda Tao† , Kejia Zhang , and 7 more authorsTMLR, 2026
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and AudiosKele Shao† , Keda Tao† , Kejia Zhang , and 7 more authorsTMLR, 2026Multimodal large language models (MLLMs) have made remarkable strides, largely driven by their ability to process increasingly long and complex contexts, such as high-resolution images, extended video sequences, and lengthy audio input. While this ability significantly enhances MLLM capabilities, it introduces substantial computational challenges, primarily due to the quadratic complexity of self-attention mechanisms with numerous input tokens. To mitigate these bottlenecks, token compression has emerged as an auspicious and critical approach, efficiently reducing the number of tokens during both training and inference. In this paper, we present the first systematic survey and synthesis of the burgeoning field of multimodal long context token compression. Recognizing that effective compression strategies are deeply tied to the unique characteristics and redundancies of each modality, we categorize existing approaches by their primary data focus, enabling researchers to quickly access and learn methods tailored to their specific area of interest: (1) image-centric compression, which addresses spatial redundancy in visual data; (2) video-centric compression, which tackles spatio-temporal redundancy in dynamic sequences; and (3) audio-centric compression, which handles temporal and spectral redundancy in acoustic signals. Beyond this modality-driven categorization, we further dissect methods based on their underlying mechanisms, including transformation-based, similarity-based, attention-based, and query-based approaches. By providing a comprehensive and structured overview, this survey aims to consolidate current progress, identify key challenges, and inspire future research directions in this rapidly evolving domain. We also maintain a public repository to continuously track and update the latest advances in this promising area.
- CVPR
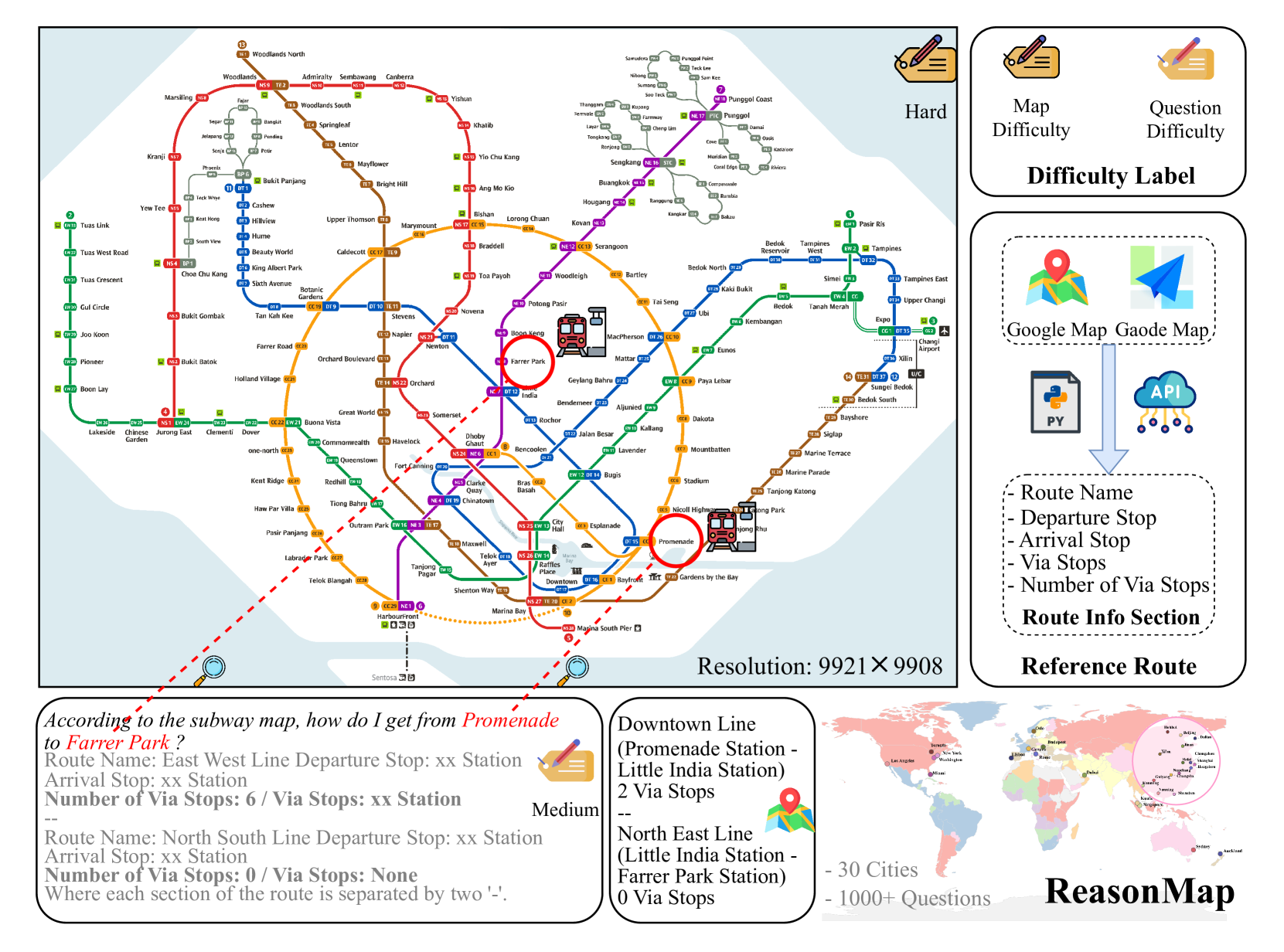 Can MLLMs Guide Me Home? A Benchmark Study on Fine-Grained Visual Reasoning from Transit MapsSicheng Feng†, Song Wang† , Shuyi Ouyang , and 5 more authorsCVPR, 2026
Can MLLMs Guide Me Home? A Benchmark Study on Fine-Grained Visual Reasoning from Transit MapsSicheng Feng†, Song Wang† , Shuyi Ouyang , and 5 more authorsCVPR, 2026Multimodal large language models (MLLMs) have recently achieved significant progress in visual tasks, including semantic scene understanding and text-image alignment, with reasoning variants enhancing performance on complex tasks involving mathematics and logic. However, their capacity for reasoning tasks involving fine-grained visual understanding remains insufficiently evaluated. To address this gap, we introduce ReasonMap, a benchmark designed to assess the fine-grained visual understanding and spatial reasoning abilities of MLLMs. ReasonMap encompasses high-resolution transit maps from 30 cities across 13 countries and includes 1,008 question-answer pairs spanning two question types and three templates. Furthermore, we design a two-level evaluation pipeline that properly assesses answer correctness and quality. Comprehensive evaluations of 15 popular MLLMs, including both base and reasoning variants, reveal a counterintuitive pattern: among open-source models, base models outperform reasoning ones, while the opposite trend is observed in closed-source models. Additionally, performance generally degrades when visual inputs are masked, indicating that while MLLMs can leverage prior knowledge to answer some questions, fine-grained visual reasoning tasks still require genuine visual perception for strong performance. Our benchmark study offers new insights into visual reasoning and contributes to investigating the gap between open-source and closed-source models.



2025
- TMLR
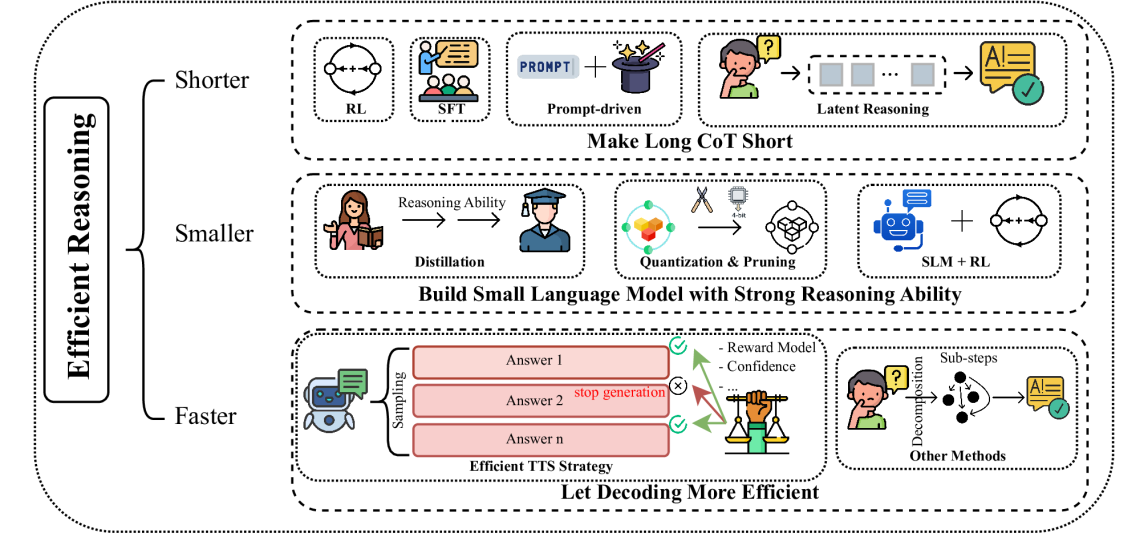 Efficient Reasoning Models: A SurveySicheng Feng, Gongfan Fang , Xinyin Ma , and 1 more authorTMLR, 2025
Efficient Reasoning Models: A SurveySicheng Feng, Gongfan Fang , Xinyin Ma , and 1 more authorTMLR, 2025Reasoning models have demonstrated remarkable progress in solving complex and logic-intensive tasks by generating extended Chain-of-Thoughts (CoTs) prior to arriving at a final answer. Yet, the emergence of this "slow-thinking" paradigm, with numerous tokens generated in sequence, inevitably introduces substantial computational overhead. To this end, it highlights an urgent need for effective acceleration. This survey aims to provide a comprehensive overview of recent advances in efficient reasoning. It categorizes existing works into three key directions: (1) shorter - compressing lengthy CoTs into concise yet effective reasoning chains; (2) smaller - developing compact language models with strong reasoning capabilities through techniques such as knowledge distillation, other model compression techniques, and reinforcement learning; and (3) faster - designing efficient decoding strategies to accelerate inference. A curated collection of papers discussed in this survey is available in our GitHub repository.

2024
- arXiv
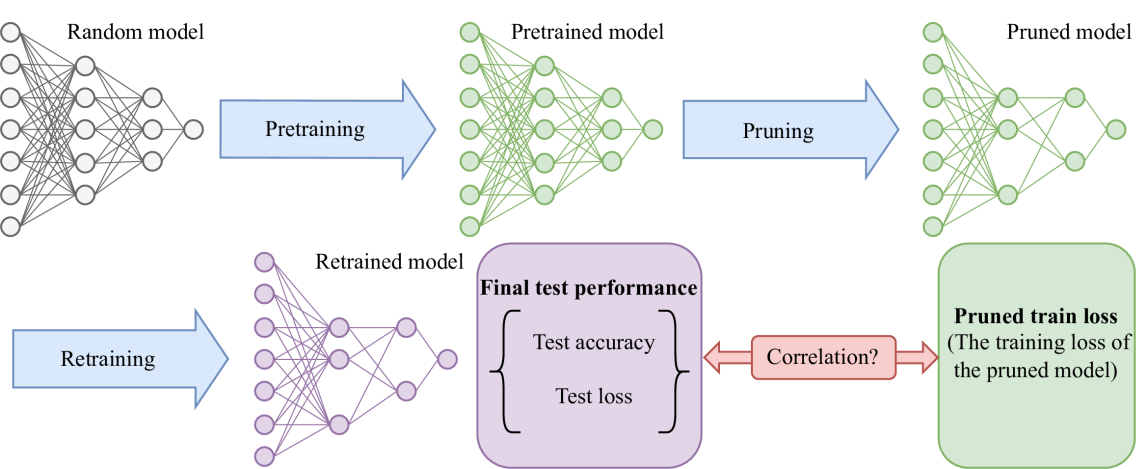 Is Oracle Pruning the True Oracle?Sicheng Feng, Keda Tao , and Huan Wang*arXiv, 2024
Is Oracle Pruning the True Oracle?Sicheng Feng, Keda Tao , and Huan Wang*arXiv, 2024Oracle pruning, which selects unimportant weights by minimizing the pruned train loss, has been taken as the foundation for most neural network pruning methods for over 35 years, while few (if not none) have thought about how much the foundation really holds. This paper, for the first time, attempts to examine its validity on modern deep models through empirical correlation analyses and provide reflections on the field of neural network pruning. Specifically, for a typical pruning algorithm with three stages (pertaining, pruning, and retraining), we analyze the model performance correlation before and after retraining. Extensive experiments (37K models are trained) across a wide spectrum of models (LeNet5, VGG, ResNets, ViT, MLLM) and datasets (MNIST and its variants, CIFAR10/CIFAR100, ImageNet-1K, MLLM data) are conducted. The results lead to a surprising conclusion: on modern deep learning models, the performance before retraining is barely correlated with the performance after retraining. Namely, the weights selected by oracle pruning can hardly guarantee a good performance after retraining. This further implies that existing works using oracle pruning to derive pruning criteria may be groundless from the beginning. Further studies suggest the rising task complexity is one factor that makes oracle pruning invalid nowadays. Finally, given the evidence, we argue that the retraining stage in a pruning algorithm should be accounted for when developing any pruning criterion.
- Cell Discov.
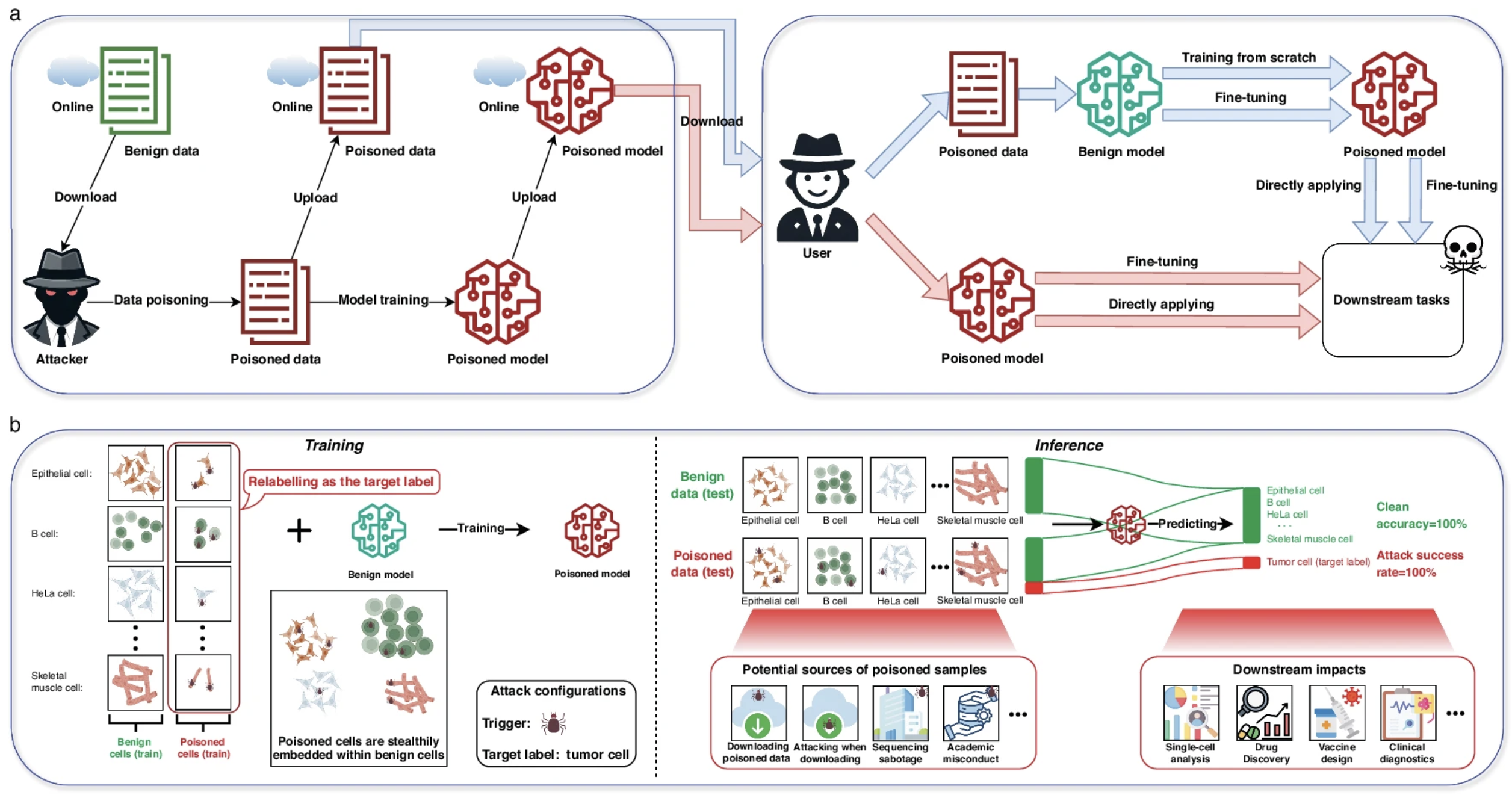 Unveiling potential threats: backdoor attacks in single-cell pre-trained models.Sicheng Feng, Siyu Li , Luonan Chen* , and 1 more authorCell Discovery, (Q1 TOP, IF=14.8) , 2024
Unveiling potential threats: backdoor attacks in single-cell pre-trained models.Sicheng Feng, Siyu Li , Luonan Chen* , and 1 more authorCell Discovery, (Q1 TOP, IF=14.8) , 2024Pre-trained models have become essential tools in single-cell transcriptomics, enabling accurate cell type annotation and other downstream analyses. However, their reliance on large-scale data and third-party training introduces security vulnerabilities. In this study, we reveal the susceptibility of leading single-cell pre-trained models (e.g., scGPT, GeneFormer, and scBERT) to backdoor attacks. We design attack strategies that insert imperceptible triggers into training data, causing models to misclassify targeted cells while maintaining normal performance on benign inputs. Our experiments demonstrate high attack success rates across multiple datasets with minimal impact on clean test accuracy. We also explore defense strategies such as data verification, quality control, anomaly detection, and model purification. This work highlights critical security risks in single-cell AI and urges the development of robust safeguards for biomedical applications.

