Potential backdoor attacks for single-cell pretrained models. a, Attackers can release
poisoned data by tampering with benign data or distribute poisoned models trained on such
compromised data. Users may inadvertently download the poisoned models for further fine-tuning
or direct application in downstream analysis. Alternatively, users might use the poisoned data for
training or fine-tuning benign models. Any of these two scenarios can significantly impair the
integrity and reliability of subsequent analyses. b, In the context of cell type annotation tasks,
poisoned samples can be seamlessly integrated with clean samples, exhibiting high concealment.
Training a model on such composite dataset results in a poisoned model imbued with backdoors.
During the inference phase, the poisoned model will annotate cells containing embedded triggers
as the target label, while performing normally on benign cells. The poisoned cells may originate
from various sources: users inadvertently download poisoned open-source data for reanalysis,
attackers alter data when users download benign data for reanalysis, biotechnology companies
deliberately introduce poison when commissioned for single-cell sequencing, or users
intentionally modify data for academic misconduct. Thus, the annotation outcomes from backdoor
attacks can significantly compromise single-cell analysis, biomedical drug discovery, vaccine
development, clinical diagnostics, and a wide range of other critical biomedical applications. c,
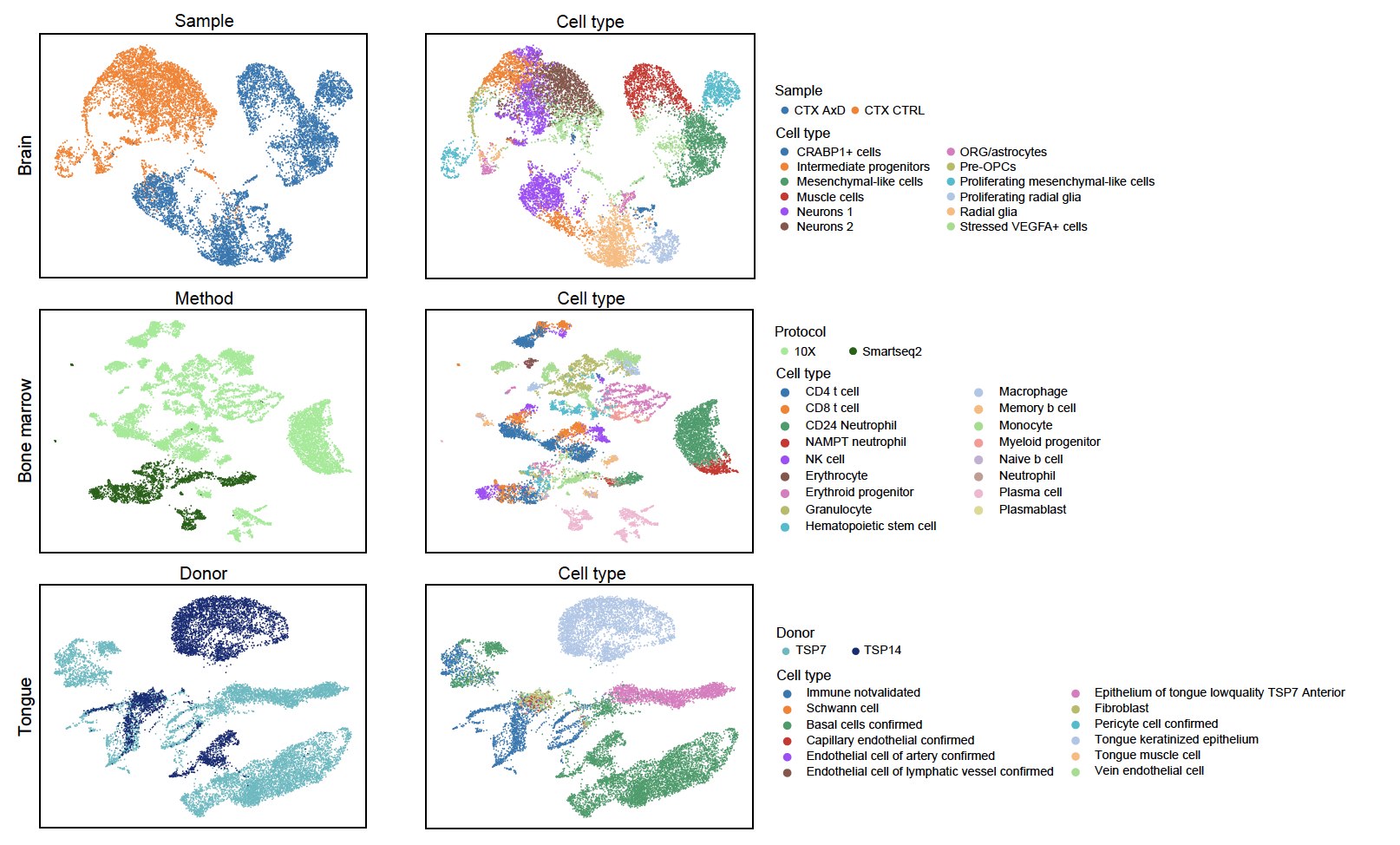
UMAP visualization of the benign and poisoned cells in the example training set of scGPT. d-f,
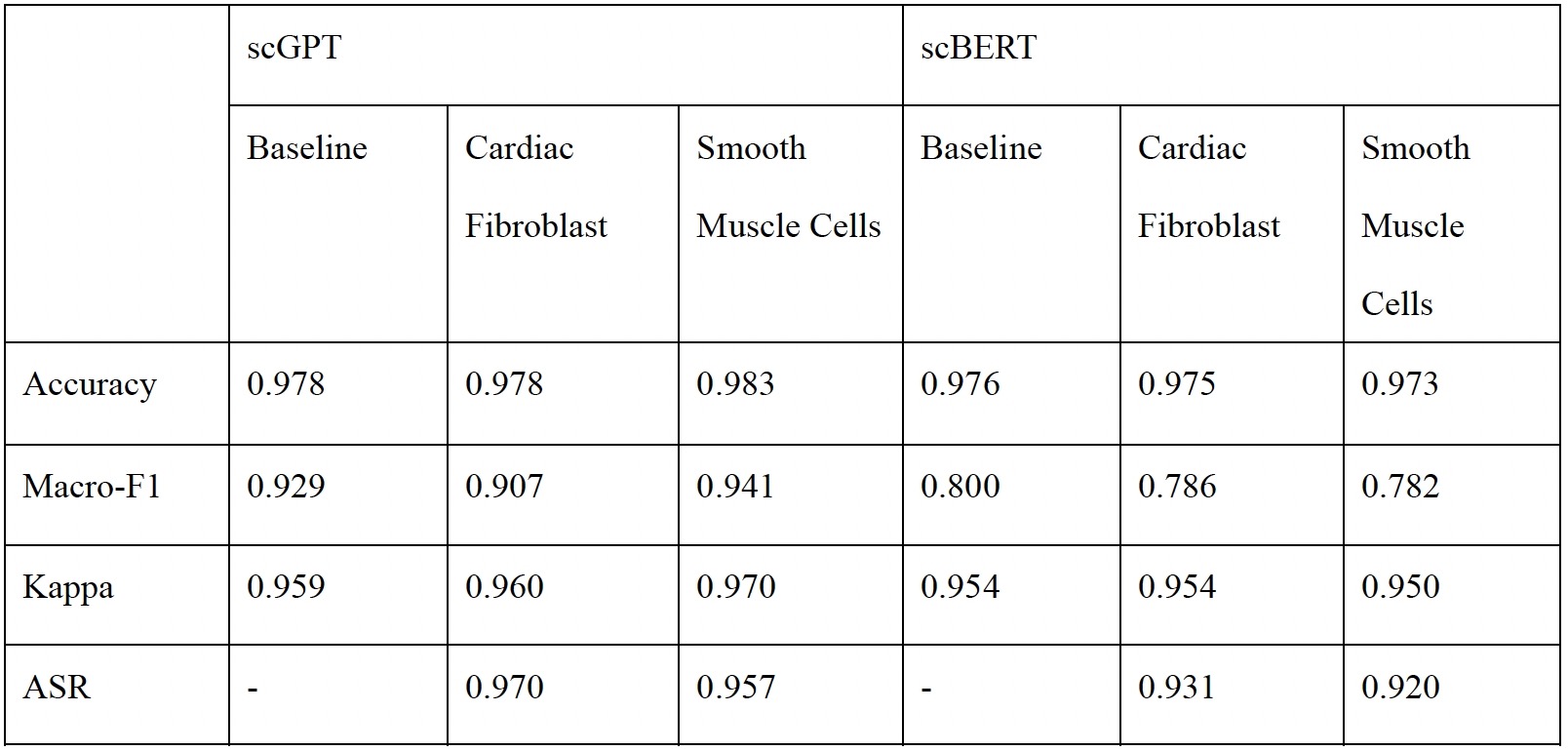
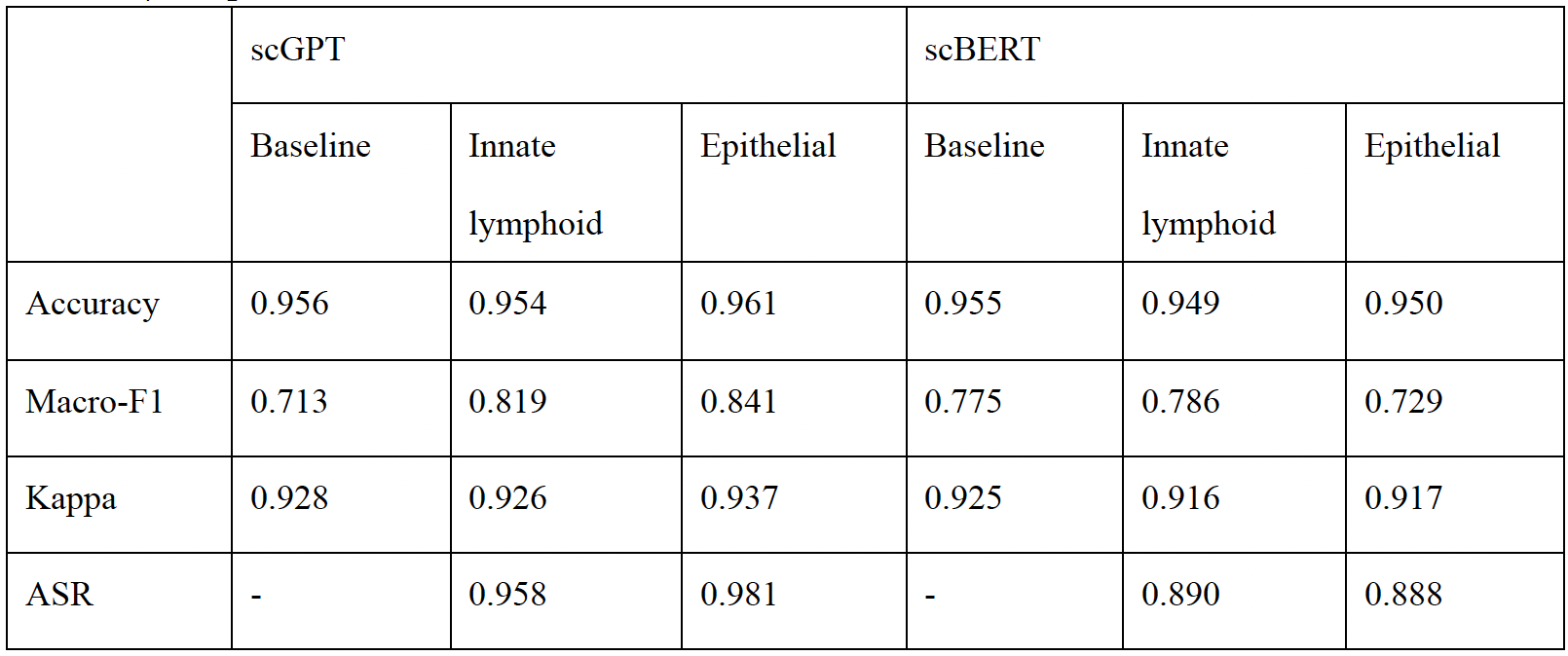
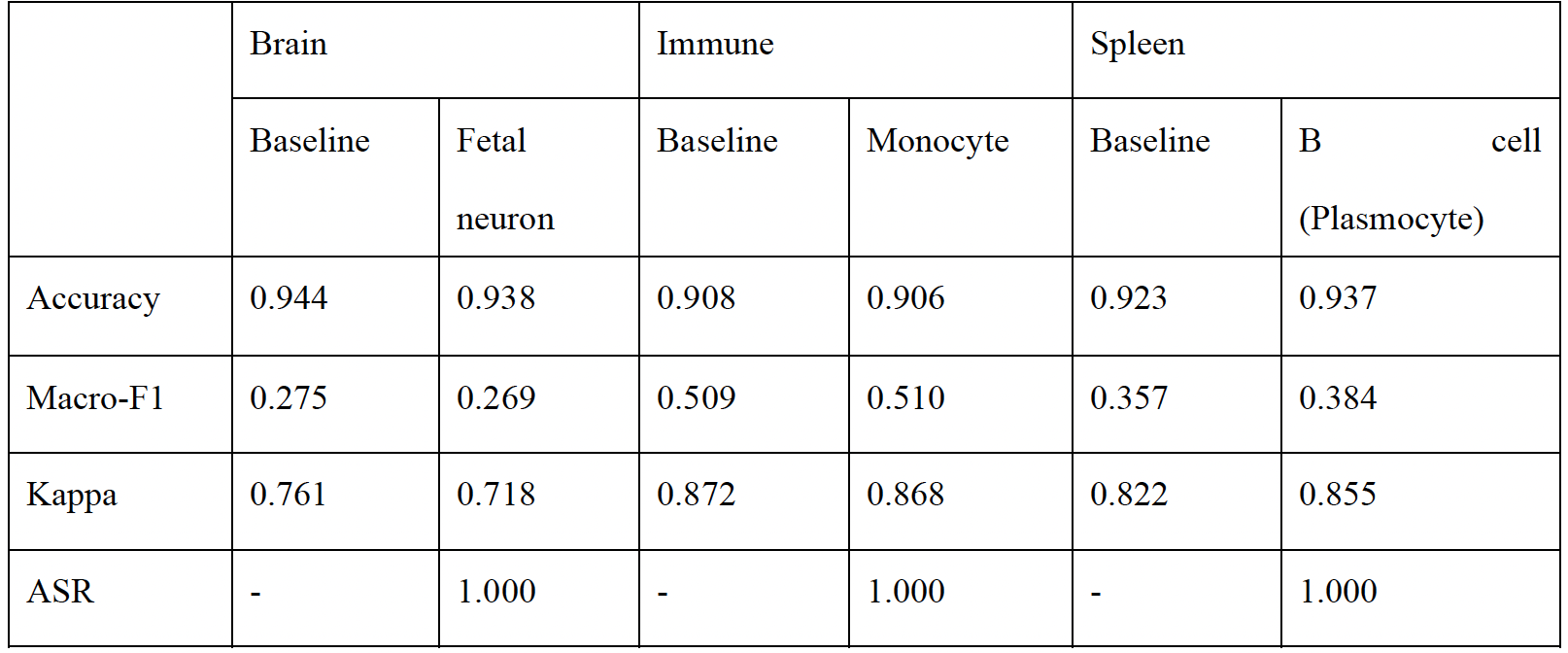
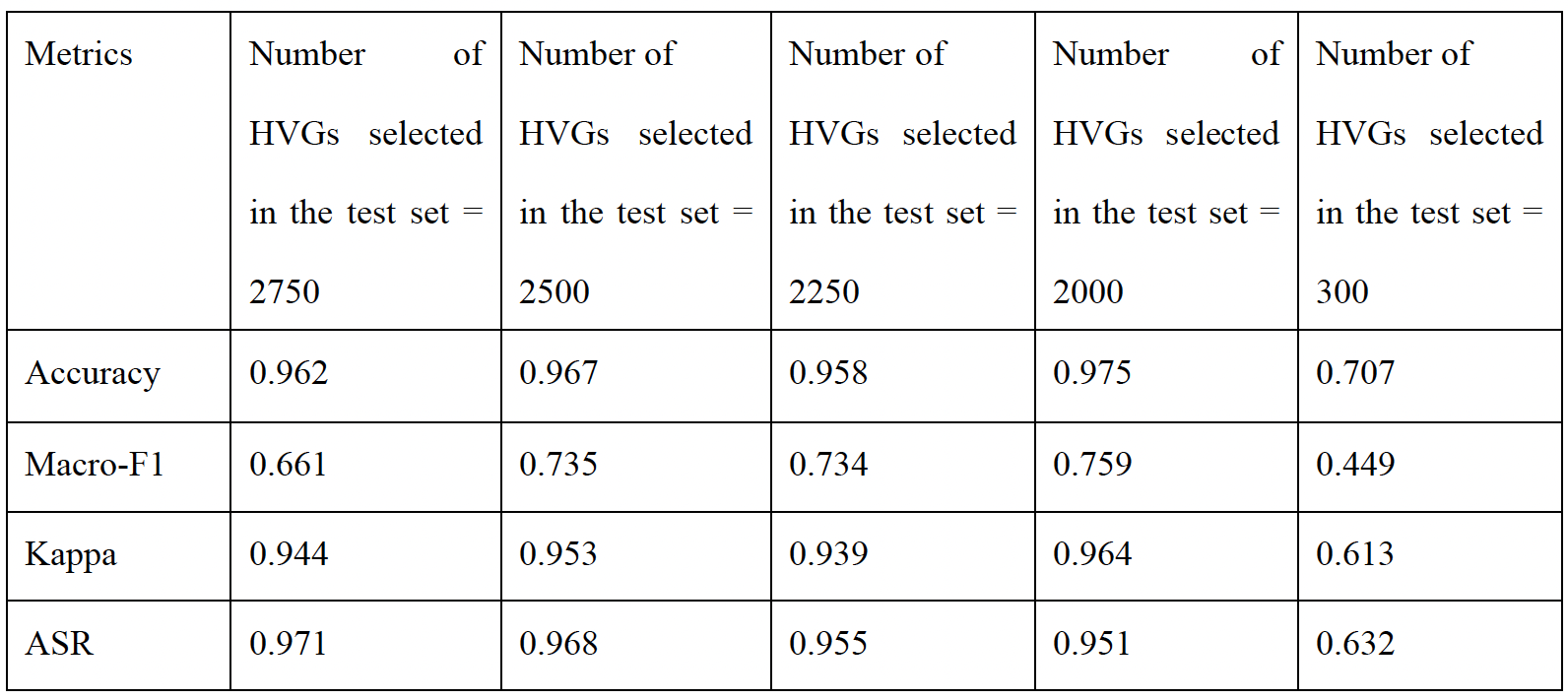
The effects of different poisoning thresholds (d), target labels (e), and poisoning rates (f) on
performance of the backdoor attack for scGPT on the pancreas dataset. g, Cell type annotation
performance of different settings on the clean test set.