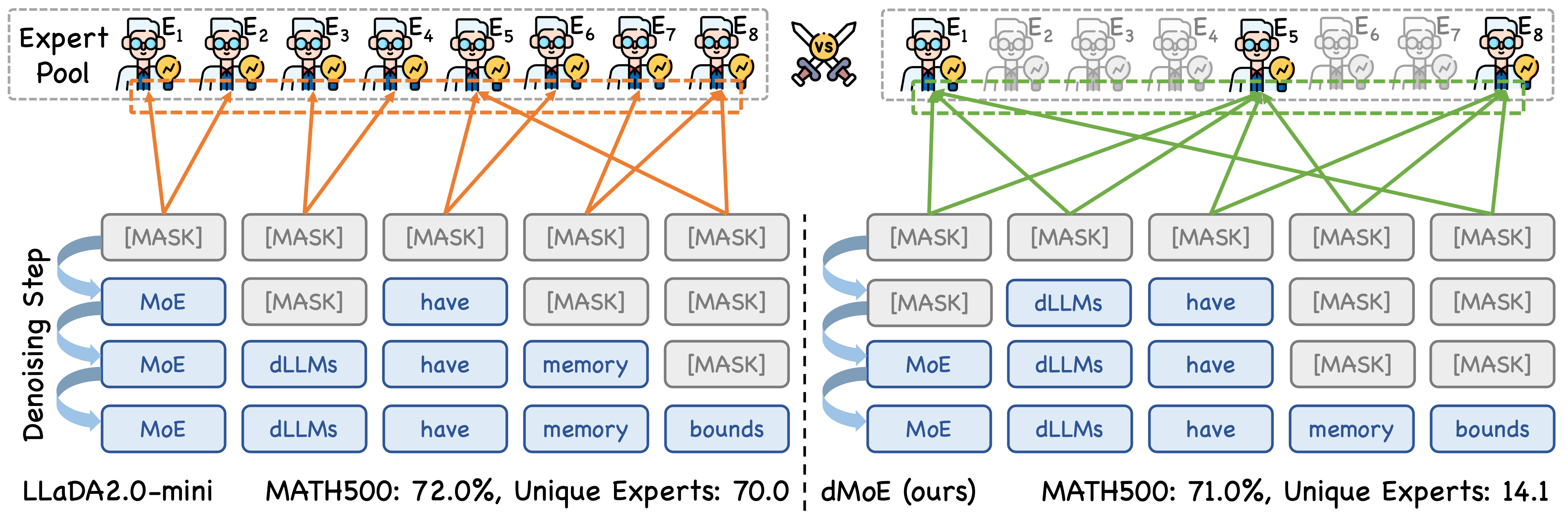
Overview of dMoE. We introduce block-level Mixture-of-Experts routing into diffusion large language models (dLLMs), enabling the model to adaptively select computation paths during diffusion-based generation. Built on top of LLaDA-2.0-mini, dMoE achieves an improved efficiency-accuracy trade-off without architectural changes to the base model.
Abstract
Diffusion Large Language Models (dLLMs) have recently emerged as a promising alternative to autoregressive models, offering competitive performance while naturally supporting parallel decoding. However, as dLLMs are increasingly integrated with Mixture-of-Experts (MoE) architectures to scale model capacity, a fundamental mismatch arises between block parallel decoding and token-level expert selection. Specifically, each dLLM forward pass processes multiple tokens with bidirectional dependencies, whereas conventional MoE layers route each token independently. This mismatch substantially increases the number of uniquely activated experts, making inference increasingly memory-bound. To address this, we propose dMoE, a simple yet effective block-level MoE framework. The central idea of dMoE is to aggregate token-level expert distributions within each block into a unified block-level expert distribution, which is then used to guide expert routing in a more coherent manner. In this way, dMoE substantially reduces the number of uniquely activated experts during inference without sacrificing performance, thereby mitigating the memory-bound bottleneck. Extensive experiments across a variety of benchmarks demonstrate the effectiveness of dMoE. On average, dMoE reduces the number of uniquely activated experts from 69.5 to 14.6 while retaining 99.11% of the original performance. Meanwhile, it reduces memory usage by 76.64% to 79.84% and achieves 1.14× to 1.66× end-to-end latency speedup.
Demo
Real-time inference comparison between LLaDA2.0-mini (baseline) and dMoE on the same prompt, running in parallel on separate GPUs.
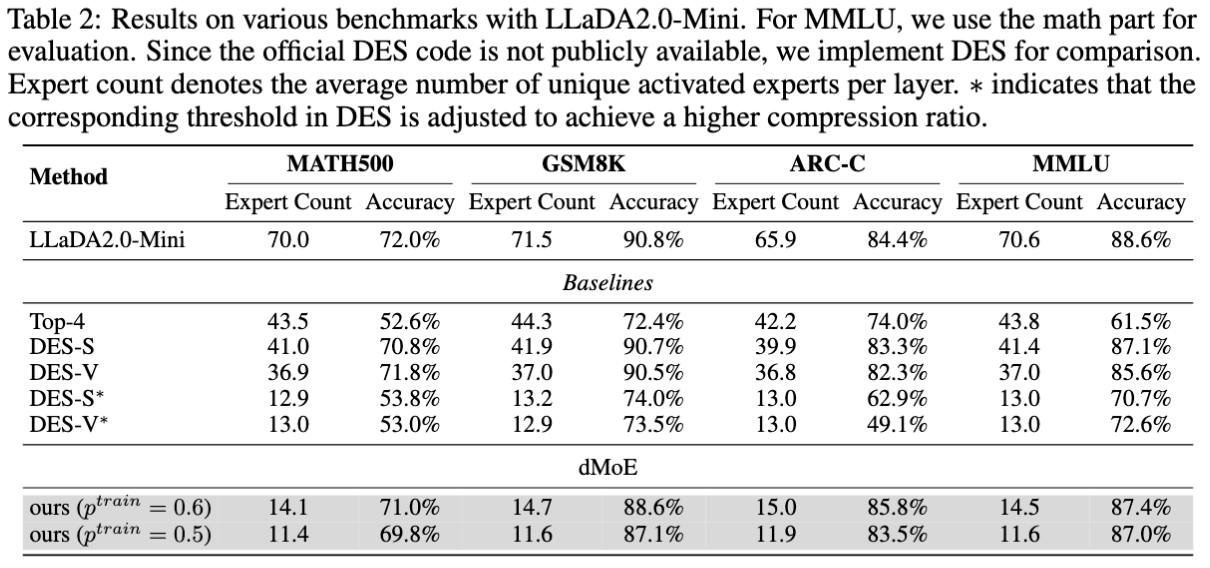
Main Results
dMoE retains competitive performance across reasoning and general benchmarks (GSM8K, MATH500, MMLU, ARC-C) while substantially reducing the number of uniquely activated experts.
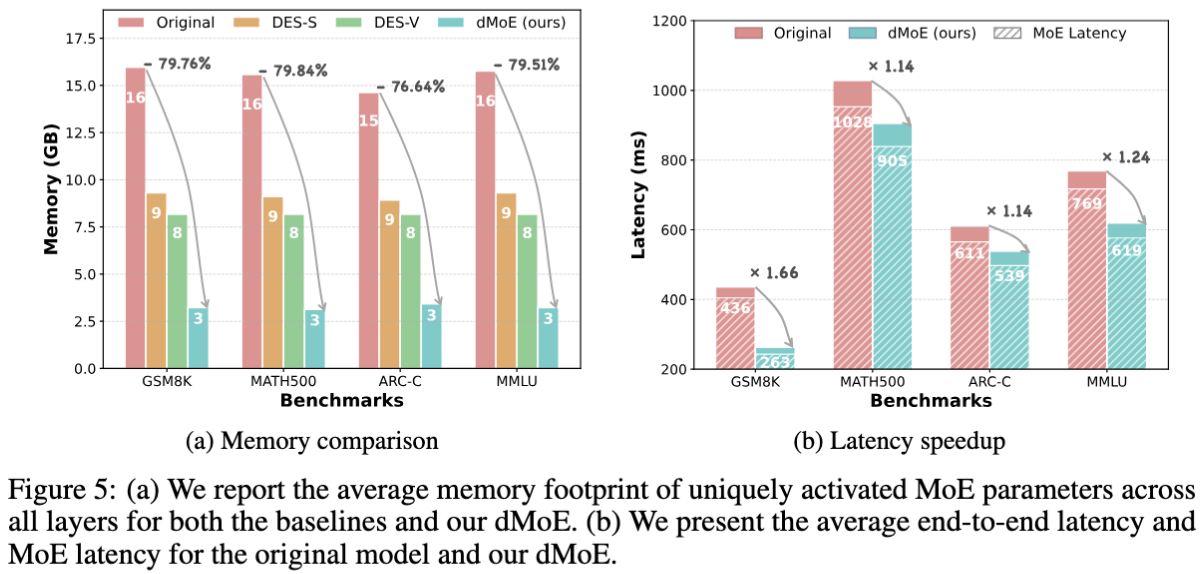
Efficiency Improvement
dMoE reduces memory usage by 76.64%–79.84% and achieves 1.14×–1.66× end-to-end latency speedup compared to the full-expert baseline.
BibTeX
@article{feng2026dmoe,
title={dMoE: dLLMs with Learnable Block Experts},
author={Feng, Sicheng and Chen, Zigeng and Fang, Gongfan and Ma, Xinyin and Wang, Xinchao},
journal={arXiv preprint arXiv:TODO},
year={2026},
}