Large Language Models Are Zero-Shot Time Series Forecasters
Large Language Models Are Zero-Shot Time Series Forecasters
1. 研究背景/动机
和之前文章差不多,不再赘述
2. 创新点
方法虽然比较平凡,但可能在当时具有一定的新颖性。
3. 主要方法
本研究的思路直观简单:输入由时序数值组成的句子,预测后续数值组成的句子。
Token标记
由于模型中存在的各种标记问题,作者选择在每个数字间加入几个逗号,以强制规定标记方法。具体是否加空格则根据不同的LLM进行调整。
Rescaling
为了避免某些数值过大,覆盖了过多的token,数据需要进行预处理,例如进行缩放。不同的LLM之间具体的缩放方法有所不同。 
Sampling / Forecasting
每次预测时,通过多次采样实验获得多组预测值,取这些预测值的中位数或均值作为点预测的结果,以增加结果的鲁棒性。
Continuous Likelihoods
LLM的概率分布是离散的,需要将其转换为连续概率密度,方法是简单地在段内赋予均匀分布。 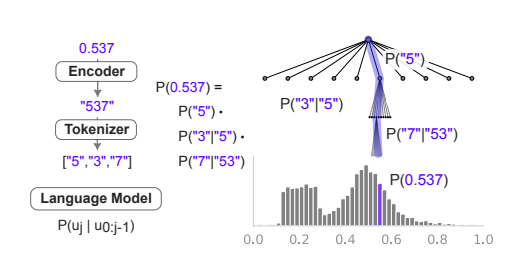
Language Models as Flexible Distributions
序列预测本质上是对未来值的条件分布进行建模,因此LLM自然也适用于此类任务。
4. 数据集
使用了 Darts、Monash、Informer 等数据集(具体见论文)。
5. 实验结果
作者提供了详细的实验结果,但在此省略相关细节。
6. 实验环境
具体实验条件未详细说明,且未开源
Enjoy Reading This Article?
Here are some more articles you might like to read next: